In contrast to a single-server MongoDB database, a MongoDB cluster allows a MongoDB database to either horizontally scale across many servers with sharding, or to replicate data ensuring high availability with MongoDB replica sets, therefore enhancing the overall performance and reliability of the MongoDB cluster.
What are clusters in MongoDB?
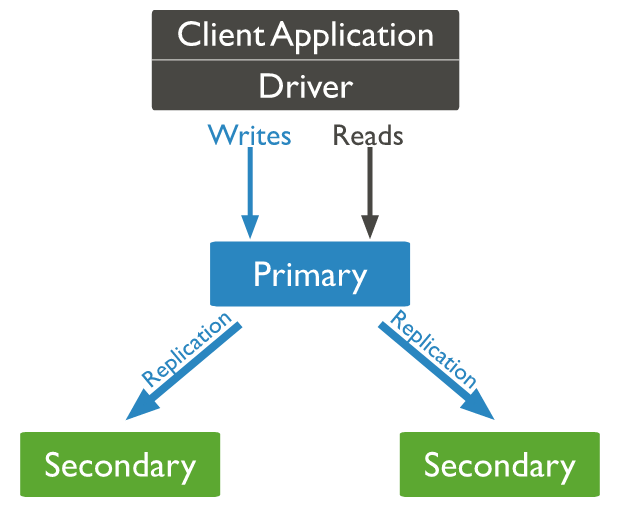
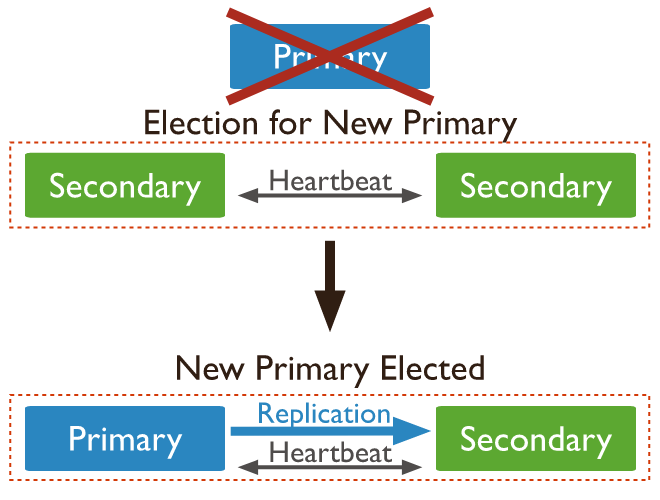
In the context of MongoDB, “cluster” is the word usually used for either a replica set or a sharded cluster. A replica set is the replication of a group of MongoDB servers that hold copies of the same data; this is a fundamental property for production deployments as it ensures high availability and redundancy, which are crucial features to have in place in case of failovers and planned maintenance periods.
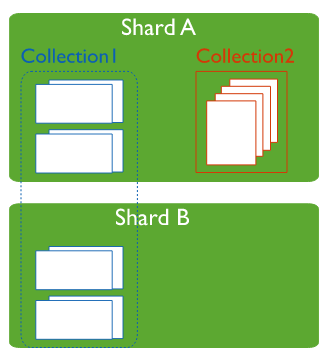
A sharded cluster is also commonly known as horizontal scaling, where data is distributed across many servers.
The main purpose of sharded MongoDB is to scale reads and writes along multiple shards.
What is MongoDB Atlas Cluster?
MongoDB Atlas Cluster is a NoSQL Database-as-a-Service offering in the public cloud (available in Microsoft Azure, Google Cloud Platform, Amazon Web Services). This is a managed MongoDB service, and with just a few clicks, you can set up a working MongoDB cluster, accessible from your favorite web browser.
You don’t need to install any software on your workstation as you can connect to MongoDB directly from the web user interface as well as inspect, query, and visualize data.
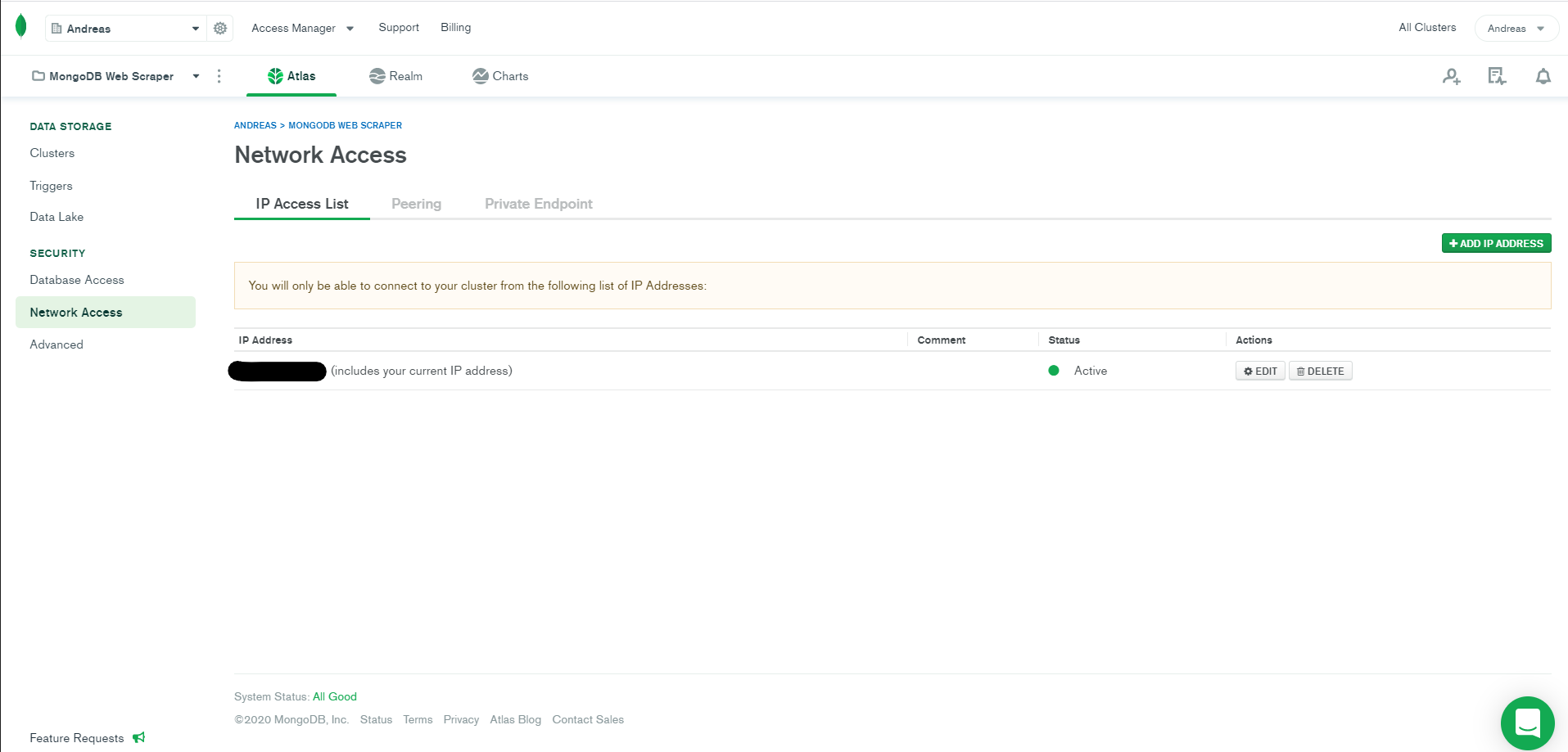
Alternatively, if you prefer working with the command line, you can connect using the mongo shell. To do this, you’ll need to configure the firewall from the web portal to accept your IP. From the homepage, navigate to Security and then Network Access. Finally, click on “Add IP Address” and add your IP: